
今回はグループごとに連番をつける方法を紹介します。
グループごとに連番をつける
やりたいこと
今回は次のようにA、Bそれぞれに連番が付与されるようにするのが目的です。
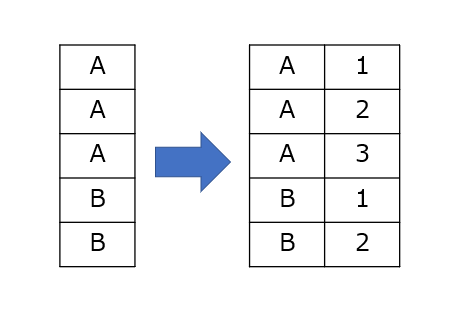
サンプルデータとして、ggplotのdiamondsデータセットを使用します。
(変数が多いので7列目までを使ってやってみます。)
|
1 2 3 4 5 6 7 8 9 10 |
head(diamonds[,1:7]) # A tibble: 6 × 7 carat cut color clarity depth table price <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> 1 0.23 Ideal E SI2 61.5 55 326 2 0.21 Premium E SI1 59.8 61 326 3 0.23 Good E VS1 56.9 65 327 4 0.29 Premium I VS2 62.4 58 334 5 0.31 Good J SI2 63.3 58 335 6 0.24 Very Good J VVS2 62.8 57 336 |
group_byとrow_numberを使って実践!
Rでグループごとに連番をつけるにはdplyrパッケージにあるgroup_byとrow_numberを使います。
group_byはグループ化するための関数、
row_numberは行番号を付与する関数、なのでなんとなくイメージしやすいかもしれません。
パッケージはtidyverseを読み込んでおくと、dplyrやggplotなどのパッケージも使えるので便利です。
|
1 |
library(tidyverse) |
サンプルのdiamondsデータセットのうち「cut」(ダイアモンドのカットの品質を示す)ごとに連番を付与してみます。
新たに「連番」という列を作成して、そこにcutごとの連番を格納して、diamonds_2というデータセットを作成します。
コードは以下のようになります。
|
1 2 3 4 |
diamonds_2 <- diamonds[,1:7] %>% group_by(cut) %>% #1.グループ化 mutate(連番 = row_number()) %>% #2.連番付与 ungroup() #3.グループ化解除 |
まずは、group_byでグループ化します。
次に、新しい列を作成するmutateで「連番」という新しい列を作り、その中にrow_numberで番号を付与しています。
最後にungroupでグループ化を解除しておきましょう。
結果を確認してみると、「連番」という列が追加されて、連番が付与されていることが確認できます。
データ数が多いとグループごとにしっかり付与されているかが分かりにくいのでfilterを使ってグループごとに想定した結果になっているか確認しておきましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
diamonds_2 %>% filter(cut=="Good") # A tibble: 4,906 × 8 carat cut color clarity depth table price 連番 <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <int> 1 0.23 Good E VS1 56.9 65 327 1 2 0.31 Good J SI2 63.3 58 335 2 3 0.3 Good J SI1 64 55 339 3 4 0.3 Good J SI1 63.4 54 351 4 5 0.3 Good J SI1 63.8 56 351 5 6 0.3 Good I SI2 63.3 56 351 6 7 0.23 Good F VS1 58.2 59 402 7 8 0.23 Good E VS1 64.1 59 402 8 9 0.31 Good H SI1 64 54 402 9 10 0.26 Good D VS2 65.2 56 403 10 |
念のため、他のグループ(cut==”Ideal”)でも連番が正しく付与されていることを確認してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
diamonds_2 %>% filter(cut=="Ideal") # A tibble: 21,551 × 8 carat cut color clarity depth table price 連番 <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <int> 1 0.23 Ideal E SI2 61.5 55 326 1 2 0.23 Ideal J VS1 62.8 56 340 2 3 0.31 Ideal J SI2 62.2 54 344 3 4 0.3 Ideal I SI2 62 54 348 4 5 0.33 Ideal I SI2 61.8 55 403 5 6 0.33 Ideal I SI2 61.2 56 403 6 7 0.33 Ideal J SI1 61.1 56 403 7 8 0.23 Ideal G VS1 61.9 54 404 8 9 0.32 Ideal I SI1 60.9 55 404 9 10 0.3 Ideal I SI2 61 59 405 10 |
arrangeと組み合わせて連番のつけ方をコントロール
並べ替えを行うarrange関数と組み合わせると、さらに応用範囲が広がります。
先ほどの例では、カットの質(cut)ごとに番号をつけるだけでしたが、カットの質ごと価格(price)順に番号を付けることもできます。
group_byでグループ化した後に、arrangeを追加します。
|
1 2 3 4 5 |
diamonds_2 <- diamonds[,1:7] %>% group_by(cut) %>% arrange(price) %>% mutate(連番 = row_number()) %>% ungroup() |
先ほどと同様にcut==”Good”に絞って結果を確認してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
diamonds_2 %>% filter(cut=="Good") # A tibble: 4,906 × 8 carat cut color clarity depth table price 連番 <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <int> 1 0.23 Good E VS1 56.9 65 327 1 2 0.31 Good J SI2 63.3 58 335 2 3 0.3 Good J SI1 64 55 339 3 4 0.3 Good J SI1 63.4 54 351 4 5 0.3 Good J SI1 63.8 56 351 5 6 0.3 Good I SI2 63.3 56 351 6 7 0.23 Good E VS2 61.8 63 357 7 8 0.23 Good F VS2 63.8 57 357 8 9 0.25 Good E VS1 63.3 60 361 9 10 0.32 Good D I1 64 54 361 10 |
arrangeはデフォルトでは昇順で並ぶので、降順に並び替えたい場合はarrange(desc())とすればOKです。
|
1 2 3 4 5 |
diamonds_2 <- diamonds[,1:7] %>% group_by(cut) %>% arrange(desc(price)) %>% mutate(連番 = row_number()) %>% ungroup() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
diamonds_2 %>% filter(cut=="Good") # A tibble: 4,906 × 8 carat cut color clarity depth table price 連番 <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <int> 1 2.8 Good G SI2 63.8 58 18788 1 2 2.07 Good I VS2 61.8 61 18707 2 3 2.67 Good F SI2 63.8 58 18686 3 4 2.01 Good H VS2 63.3 55 18640 4 5 2.01 Good G SI1 60.3 60 18625 5 6 3.01 Good H SI2 57.6 64 18593 6 7 2.01 Good G SI1 63.1 59 18572 7 8 2.01 Good H VS2 57.8 60 18561 8 9 2.4 Good I SI1 56.9 62 18541 9 10 2.66 Good H SI2 64.3 60 18495 10 |
他にも組み合わせ次第で活用の幅は広がるかもしれません。
ぜひ試してみてください!


コメント